Lichess rating to FIDE Elo : here we go again
Since I was a child, I was a passionate chess player who was also invested in the life of my club to the point of obtaining the DIFFE certification to become the chess initiator of a group of children. Long story short, with college I didn’t have time anymore to play competitively and I had to abandon my group of gifted young players and the intense tournaments.
Since then, I continued to play casually on Lichess but I think my chess level became much lower than before. But what is it really ? What would be my level if I went back to competition ?
What I discovered recently is that I am clearly not the only one to ask myself this question. In fact, it appeared to me that it is a very popular topic of discussion among Lichess players and statistics enthusiasts. There are three main posts on Reddit on the subject (#1, #2 and #3) and one main post on the Lichess forum (#4). The website Chessgoals.com (#5) devotes also one page to the comparison of ratings between Lichess rating and FIDE Elo.
These different methods give very different results :

For the formula using the classical or blitz rating, I replace it with my rapid rating because I only play rapid. Knowing that, my FIDE Elo could be between 1520 and 1820 according to these methodologies. This large gap could be mainly explained by the sample construction and the data handling treatments.
What are the methodologies of already existing correspondences between Lichess rating and FIDE Elo ?
With the method #1 and #2, the source of the data players is not indicated but I think it is the standard chess Lichess database. This database contains all games played by all players on Lichess.com. For example in March 2021, there were 100 million games played for a total of 27 Gb compressed (.pgn.bz2) and 300 Gb decompressed. With this database, we could obtain the pseudo of every players of Lichess.com. Then, I suppose #1 and #2 used the Lichess API to get the user public data, such as rating, rating deviations, number of games played, title, country, name, bio and self-reported FIDE Elo. #1 indicates that 3% of players self-report a FIDE Elo.
#1 removes every player that played less than 50 games (it is not indicated in which category), self-reported FIDE Elo outliers (FIDE rating above 2900, the record is 2882, and below 1000), and every point with a residual greater than two standard deviations of a first linear regression prediction. As #2 suggests, the main problem of this approach is the reliability of self-reported FIDE ratings. We can clearly see a strong number of people indicating a FIDE Elo equals to 3000 or inferior to 1000, which is impossible. It is very likely that , on average, the players indicate an ELO higher than the reality.
The solution proposed by #2 is to match the information of Lichess database with the FIDE database, with a key composed of the name, the title, and the country. The objective is to obtain the true FIDE rating of each player. #2 doesn’t indicate if it use the standard rating of rapid rating of FIDE. Finally, to be sure to have the correct player, #2 only keep the data point if the player’s self-reported FIDE rating matches the one I looked up. #2 doesn’t indicate how many players he lost with these criteria. There is no information about how the matching on the name was done (fuzzy or exact matching, which threshold was used).
My hypothesis is that players don’t update their self-reported FIDE Elo on Lichess.com often so it is totally normal that there is a little difference between the two. By recreating the database, we can see that 78% of Lichess account don’t indicate a country, 89% don’t indicate a name and 97,6% don’t indicate a FIDE Rating : using a key of country, name, title and self-reported FIDE rating is a very strong constraint and we lose a lot of players. Also, the quality of the variable country is sometimes poor with 3295 players indicating “pirates” and 2868 indicating “lichess”. Concerning the name, we have 19 accounts that are copycats of Magnus Carlsen (same name, same country, same Elo) and 104 accounts with all the information of Drozdzynski Daniel. More generally, 2% of players have at least two accounts or some copycats, generally popular chess champions. Because of that, the sample distribution is biased and we have some “Magnus Carlsen” fake accounts with a Lichess rapid of 1400 if we don’t correct the data. This is fun knowing that the real account of Magnus Carlsen is @DrNykterstein and doesn’t have indicated a name, a country or a FIDE Elo.
Rapidly, #3 and #4 exercises are closed to #1 but with a smaller sample of players : #3 analyzes only the 89 000 players following Magnus Carlsen account and #4 analyzes only 300 000 random accounts (21% of the total number of players). #5 doesn’t present its sample or methodology on its website and is based on a survey.
A proposition for a new methodology
Because the five predictions of my FIDE Elo are so different from each other with these methods, I decided to investigate myself the problem and to tackle some potential limitations that I identified in the already existing exercises. This could also be the occasion to explain to you how to do it if you want to reproduce the analysis.
- Collection of the list of pseudo of all the players of lichess.com and their centipawns loss
To do this analysis, I downloaded the standard chess Lichess database on https://database.lichess.org/. Because the raw size of the PGN represents 300 Gb , it was impossible for me to decompress it entirely. I decided to stream decompress it with the Python package bz2. This package will decompress line by line all the document. I used the package tqdm to have a progress bar for the process and I exported the information that I want to extract in a json file as it goes along. My code is slightly more complex than if we want only the retrieve the complete list of account pseudos because I want to see if using the centipawns loss improves the prediction score of our algorithm.
2. Scraping of the accounts of all Lichess players
After having obtained the complete list of the 1.437.315 account pseudos of Lichess.com, we need to scrape the information on their profiles with the Lichess API. Information we want to scrape is the rapid rating, rapid RD (rating deviation), number of games in rapid, the same three variables for blitz and puzzle, the country, the first name, the last name, the self-reported FIDE rating and the title. If a user has a FIDE title or a National title, the staff of Lichess can add it to its Lichess account, however he will need to prove that he is who he claims to be, and that he has the title in question. He can choose to remain anonymous towards other users. The main problem with the Lichess API is that it is very slow : maximum three requests per second. When you have 1.4 million accounts to scrape, this means you have to run the script for 5,4 days, scraping around 10800 accounts per hour. The other thing to keep in mind when coding this script is the fact that not all users have completed all information, then we should use a lot of try/except.
I share with you the entire database on my Dropbox, you can download it at this link if you want to do your own analyses. This database contains all the information of Lichess accounts at the end of April 2021. In the future, if you want to update the database, you will be able to do it with the code I share in this post.
3. Download of the FIDE rating database and matching of Lichess profiles
The FIDE rating database contains the rapid of all chess players of the world who are part of a national federation. We can also have other variables such as the title of the player, its age and its legal gender. To match Lichess accounts to FIDE profiles, I do a fuzzy matching on the variable name with the package rapidfuzz. It is not a popular fuzzy matching package but it is way faster than fuzzywuzzy. I use the scorer “token_sort_ratio” which works the best for our problem : the way I constructed the variables name with Lichess data make it first name + last name, but it is the contrary on the FIDE database. Also, on Lichess there is usually up to three first names of a player, but on Lichess there is only the main first name. token_sort_ratio attempts to account for similar strings out of order.
Among the 1.4 million Lichess accounts, 33 276 have self-declared a FIDE Elo (2,3%), among whom 24 784 have also indicated a name (1,7%). We were able to find 9349 of those Lichess players in the FIDE database after deleting the accounts in double and the impersonation accounts. This was done with two treatments : deletion of the 73 accounts with a FIDE Elo > 2400 but without a title on Lichess, and deletion of all the accounts with the same name except the one with the rating the closest to the FIDE Elo identified.
The subsample of FIDE players on Lichess that indicated their names is not representative of the entire community of players : they are very much stronger, with a median rapid rating of 2044 vs 1505 for the entire community of players. With a rapid rating of 1900, Lichess tells me that I am stronger than 88% of the players of Lichess, but it forgets to tell me that I am weaker than 62% of FIDE players on Lichess …
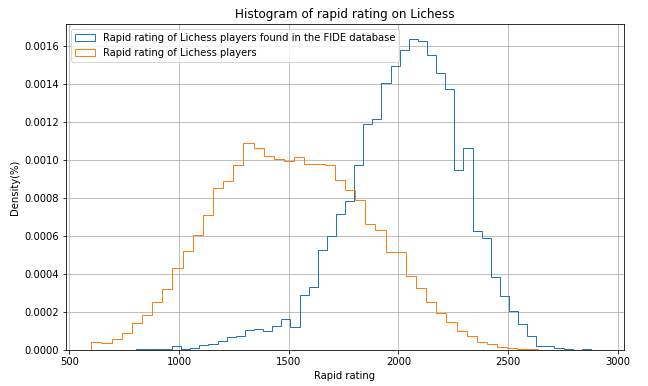
4. Estimation of the correspondence between Lichess ratings and Elo
The database is now ready and we have done very few cleaning : just removing the copycats, the double accounts and the liars on the self-reported variable “FIDE rating”. Now, for the estimation of the correspondence between rapid rating and FIDE Elo, we will select only players who have a non-provisional rapid (rapid RD < 100) and I delete the 1% of outliers on the variable difference_rapid, which is the FIDE Elo minus the rapid rating. For the correspondence between blitz rating and FIDE Elo, I will do the same thing but on the variable blitz rating.
I don’t apply as much cleaning as the other people that did a similar study and it is voluntary. I think that deleting 10% of the sample with the rule of deleting everything that is higher than 2 standard deviations could create artificially a strong linear correlation between rapid rating and FIDE Elo that could not exist in the raw data. In addition, by using only clean data (Lichess rapid rating and FIDE Elo) except of self-reported Elo, the data is naturally very clean. Because there is a high number of observations, I plot some density scatterplots.
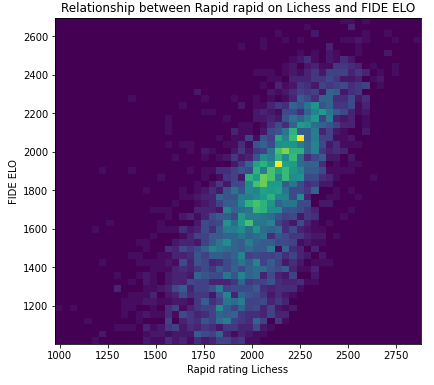
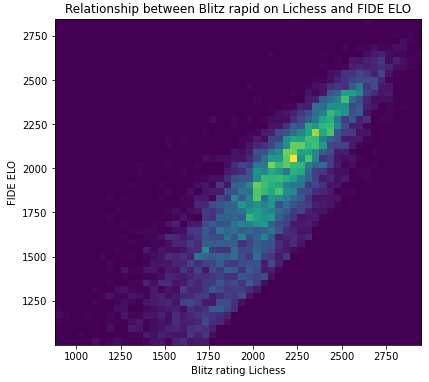
What appears very clearly is that there is way less noise at the top of the distribution than at the bottom, and that the correlation between blitz rating and Elo is stronger than between rapid rating and Elo. Nevertheless, it exists a strong correlation between the two variables.
I try two strategies to estimate the correspondence between lichess rating (rapid and blitz) and FIDE Elo : a linear regression and a decision tree with bins of 50 points of rating.
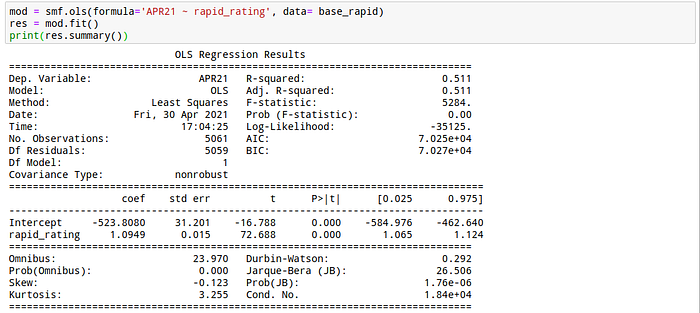
- Linear regression between FIDE Elo (during April 2021) and Lichess rapid rating
- Linear regression between FIDE Elo (during April 2021) and Lichess blitz rating
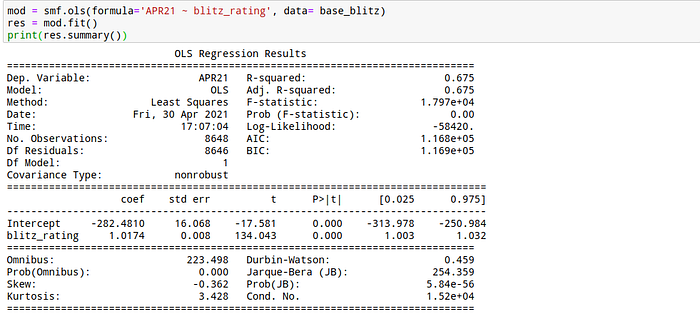
We can see that the relationship between blitz rating and Elo is stronger than between rapid rating and Elo, but the R² is higher than 50% for both regressions. I am personally a rapid player, so my 1900 rapid rating could be a 1557 FIDE Elo. This result is close to the estimation of the formula #1, #3 and maybe #5, but very far from #2 and #4.
Could the relationship be not perfectly linear ? To answer this question and create a confidence interval, I use a decision tree. I added to the plot a 90% confidence interval.
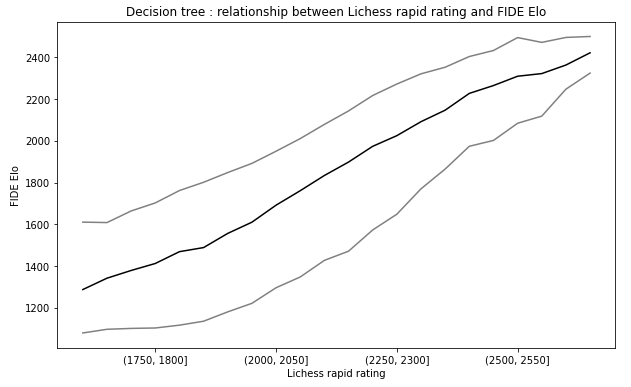
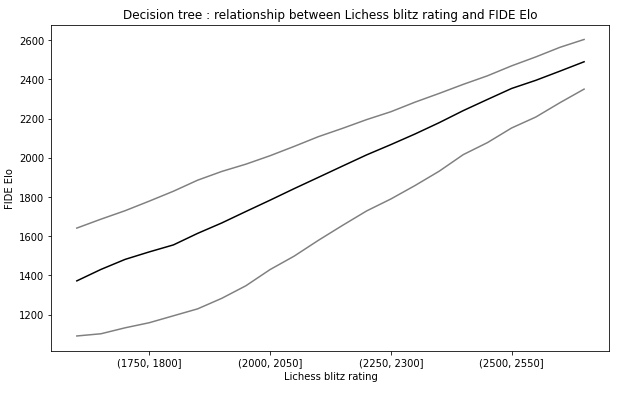
The first result is that the relationship is very linear in both cases, but maybe a little bit less for the rapid rating/Elo relationship. The curve is a little bit convex for the first quantiles and a little bit concave for the last quantiles. We can also observe that the confidence interval is smaller for the blitz-Elo relationship. We have heteroscedasticity in both cases.
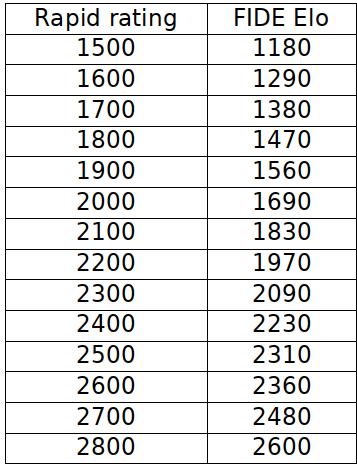
5. Does the quality of the play improve the prediction of the FIDE Elo ?
Do you remember when we scraped the centipawns loss of every games during March 2021 of every players ? Let’s see if this information improve the prediction of the FIDE Elo. Some research papers already worked on translating quality of play into a perceived Elo rating. and tried to identify a relationship between gain per move and expected score. We can cite for example Ferreira (2012) and Haworth et al. (2015).
For our analysis, the first step is to generate the variables of interest based on the centipawns variations of each move. A recurrent debate on the forums is if there is a relationship between the average centipawns loss (average quality of play) and the Elo, or between the quantile centipawns loss (average quality of the x% worst moves) and the Elo. Some people say that what is important is how often you do a blunder, rather than how you play on average. To test that hypothesis, I generated a high quantity of variables : the quality of play of the 5% worst moves, 10%, 25%, 50%, 75%, the average centipawns loss, the probability of making an “error” (centipawns loss superior to 1 and inferior to 2), a “blunder” (centipawns loss superior to 2), a good move (< -1) and a very good move (<-2)
By doing linear regressions with only one regressor at a time, what we observe is that how bad you play is more correlated with the FIDE Elo than how good you play. The R² of the regression with only one regressor which is the centipawns loss during the 10% worst move (quantile10) is 10.6% whereas it is only 8.9% for the quantile 50 and 4.7% for the quantile 75.
R² of the regression FIDE Elo ~ regressor, with the regressor being :
- Quantile 5 : 8.1%
- Quantile 10 : 10.6%
- Quantile 25 : 10.8%
- Quantile 50 : 8.9%
- Quantile 75 : 4.7%
- Mean centipawns loss : 6.4%
- Probability of making an error : 12.2%
- Probability of making a blunder : 10.6%
- Probability of making a good move : 0.004%
- Probability of making a very good move : 0.001%
The probability of making a blunder goes from 11% at the Elo 1000, to 4,7% at the Elo 2600 in our dataset.
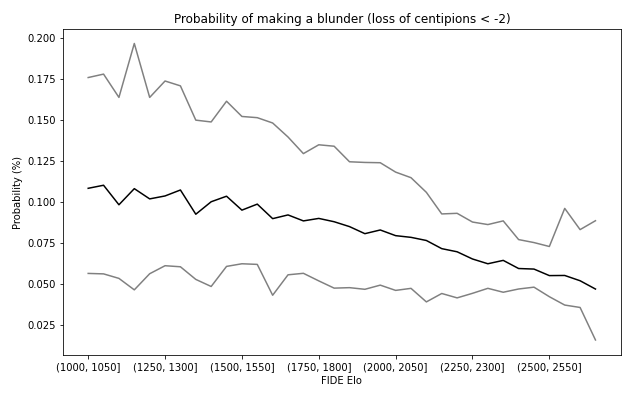
Meanwhile, the mean centipawns loss is pretty stable from -0.76 (Elo 1500) to -0.47 (Elo 2600) in our dataset
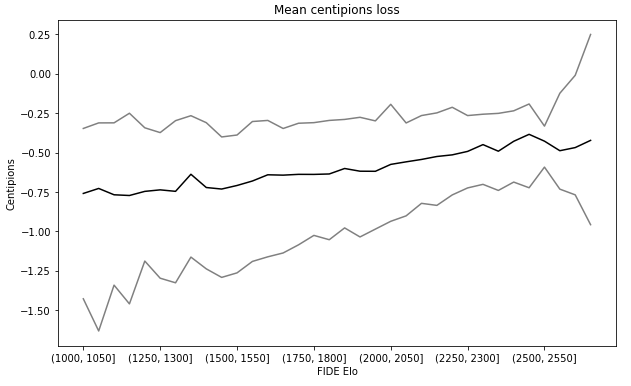
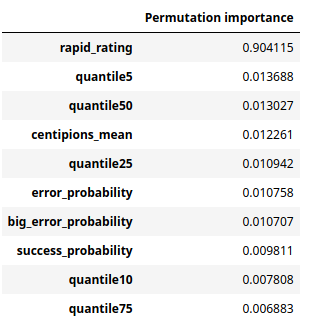
However, it is important to put into perspective the interest of this variable to predict the FIDE Elo : when we add the probability of making a blunder to the linear regression FIDE Elo ~ rapid_rating, the R² increases only by 0.5pp (points of percentage). And with a random forest, adding all the variables we created reduce the RMSE (root-mean-squared error) by around 2% only. We go from a RMSE of 249 with only the variable rapid_rating, to 244 with all the variables, and the permutation importance of the rapid rating is higher than 90%.
Conclusion :
- FIDE players have an average score 500 points higher than all Lichess players.
- The correlation between Lichess blitz rating and FIDE Elo is stronger than between rapid rating and Elo, but both are superior to 50% and significant at 1%.
- The probability of making a blunder explains 12% of the variance of the FIDE Elo alone, but contributes to only +0.5pp when the rapid rating is already a regressor.
- I am pretty bad at chess.
For your information, this article was written by a French person. Please excuse me if you find any spelling or grammar mistake. If you have any question or if you want more information about a part of the analysis, please don’t hesitate to contact me at antoine[dot]baena[@]outlook[dot]com.
References :
Ferreira, D. R. (2012). Determining the strength of chess players based on actual play. ICGA journal, 35(1), 3–19.
Haworth, G., Biswas, T., & Regan, K. (2015, July). A comparative review of skill assessment: performance, prediction and profiling. In Advances in Computer Games (pp. 135–146). Springer, Cham.
